Was ist Web Scraping? So sammeln Sie Daten von Websites
Werbung
Web Scraper sammeln automatisch Informationen und Daten, auf die normalerweise nur durch den Besuch einer Website in einem Browser zugegriffen werden kann. Auf diese Weise eröffnen Web-Scraping-Skripte eine Vielzahl von Möglichkeiten in den Bereichen Data Mining, Datenanalyse, statistische Analyse und vielem mehr.
Warum Web Scraping nützlich ist
Wir leben in einer Zeit, in der Informationen leichter verfügbar sind als zu jeder anderen Zeit. Die Infrastruktur, mit der genau diese Wörter, die Sie lesen, bereitgestellt werden, ist ein Kanal für mehr Wissen, Meinungen und Nachrichten als jemals zuvor für Menschen in der Geschichte der Menschen.
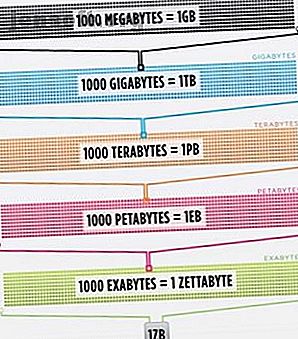
So sehr, dass das Gehirn der intelligentesten Person, das zu 100% effizienter ist (jemand sollte einen Film darüber machen), immer noch nicht in der Lage wäre, 1/1000 der im Internet gespeicherten Daten allein in den USA zu speichern .
Cisco schätzte im Jahr 2016, dass der Datenverkehr im Internet ein Zettabyte (1.000.000.000.000.000.000.000 Bytes) oder eine Sextillion Bytes überschritt (weiter, kichern Sie bei Sextillionen). Ein Zettabyte entspricht etwa viertausend Jahren Streaming von Netflix. Das wäre gleichbedeutend damit, dass Sie, unerschrockener Leser, The Office von Anfang bis Ende streamen, ohne 500.000 Mal anzuhalten.

All diese Daten und Informationen sind sehr einschüchternd. Nicht alles ist richtig. Nicht viel davon ist für den Alltag relevant, aber immer mehr Geräte liefern diese Informationen von Servern auf der ganzen Welt direkt an unsere Augen und in unser Gehirn.
Da unsere Augen und unser Gehirn nicht wirklich mit all diesen Informationen umgehen können, hat sich Web Scraping als nützliche Methode zum programmgesteuerten Sammeln von Daten aus dem Internet herausgestellt. Web Scraping ist der abstrakte Begriff für das Extrahieren von Daten von Websites, um sie lokal zu speichern.
Denken Sie an eine Art von Daten, und Sie können sie wahrscheinlich sammeln, indem Sie das Web durchsuchen. Immobilieneinträge, Sportdaten, E-Mail-Adressen von Unternehmen in Ihrer Nähe und sogar der Text Ihres Lieblingskünstlers können mithilfe eines kleinen Skripts gesucht und gespeichert werden.
Wie erhält ein Browser Webdaten?
Um Web-Scraper zu verstehen, müssen wir zunächst verstehen, wie das Web funktioniert. Um zu dieser Website zu gelangen, haben Sie entweder „makeuseof.com“ in Ihren Webbrowser eingegeben oder auf einen Link von einer anderen Webseite geklickt (sagen Sie uns, wo genau wir das wissen wollen). In jedem Fall sind die nächsten Schritte gleich.
Zuerst nimmt Ihr Browser die URL entgegen, die Sie eingegeben oder angeklickt haben (Tipp: Bewegen Sie den Mauszeiger über den Link, um die URL am unteren Rand Ihres Browsers anzuzeigen, bevor Sie darauf klicken, um Punks zu vermeiden) und bildet eine "Anfrage" zum Senden zu einem Server. Der Server verarbeitet dann die Anforderung und sendet eine Antwort zurück.
Die Antwort des Servers enthält HTML-, JavaScript-, CSS-, JSON- und andere Daten, die erforderlich sind, damit Ihr Webbrowser eine Webseite für Ihr Sehvergnügen erstellen kann.
Überprüfen von Webelementen
Moderne Browser erlauben uns einige Details zu diesem Prozess. In Google Chrome unter Windows können Sie Strg + Umschalt + I drücken oder mit der rechten Maustaste klicken und Inspizieren auswählen. Das Fenster zeigt dann einen Bildschirm an, der wie folgt aussieht.

Am oberen Rand des Fensters befindet sich eine Liste mit Optionen mit Registerkarten. Im Moment ist die Registerkarte Netzwerk von Interesse. Daraufhin werden Details zum HTTP-Datenverkehr angezeigt (siehe unten).

In der unteren rechten Ecke sehen wir Informationen zur HTTP-Anfrage. Die URL ist das, was wir erwarten, und die "Methode" ist eine HTTP "GET" -Anforderung. Der Statuscode aus der Antwort wird als 200 aufgeführt. Dies bedeutet, dass der Server die Anforderung als gültig angesehen hat.
Unter dem Statuscode befindet sich die Remoteadresse, die öffentlich zugängliche IP-Adresse des makeuseof.com-Servers. Der Client erhält diese Adresse über das DNS-Protokoll. Warum das Ändern der DNS-Einstellungen die Internetgeschwindigkeit erhöht Warum das Ändern der DNS-Einstellungen die Internetgeschwindigkeit erhöht Das Ändern der DNS-Einstellungen ist eine der geringfügigen Verbesserungen, die sich auf die tägliche Internetgeschwindigkeit auswirken können. Weiterlesen .
Im nächsten Abschnitt werden Details zur Antwort aufgeführt. Der Antwortheader enthält nicht nur den Statuscode, sondern auch die Art der Daten oder Inhalte, die die Antwort enthält. In diesem Fall betrachten wir "text / html" mit einer Standardcodierung. Dies sagt uns, dass die Antwort buchstäblich der HTML-Code zum Rendern der Website ist.

Andere Arten von Antworten
Darüber hinaus können Server Datenobjekte als Antwort auf eine GET-Anforderung zurückgeben, anstatt nur HTML für die Darstellung der Webseite. Anwendungsprogrammierschnittstelle (oder API) einer Website Was sind APIs und wie ändern offene APIs das Internet? Was sind APIs und wie ändern offene APIs das Internet? Haben Sie sich jemals gefragt, wie Programme auf Ihrem Computer und auf den von Ihnen besuchten Websites "sprechen"? zueinander? Read More verwendet normalerweise diese Art des Austauschs.
Wenn Sie die Registerkarte Netzwerk wie oben gezeigt durchsehen, können Sie feststellen, ob es diese Art des Austauschs gibt. Bei der Untersuchung der CrossFit Open-Bestenliste wird die Aufforderung angezeigt, die Tabelle mit Daten zu füllen.

Durch Klicken auf die Antwort werden die JSON-Daten anstelle des HTML-Codes zum Rendern der Website angezeigt. Daten in JSON sind eine Reihe von Bezeichnungen und Werten in einer geschichteten, umrissenen Liste.

Das manuelle Parsen von HTML-Code oder das Durchlaufen von Tausenden von Schlüssel / Wert-Paaren von JSON ähnelt dem Lesen der Matrix. Auf den ersten Blick sieht es nach Kauderwelsch aus. Möglicherweise sind zu viele Informationen vorhanden, um sie manuell zu decodieren.
Web Scraper zur Rettung!
Bevor Sie jetzt nach der blauen Pille fragen, um das Problem zu lösen, sollten Sie wissen, dass wir den HTML-Code nicht manuell entschlüsseln müssen! Unwissenheit ist keine Wonne, und dieses Steak ist köstlich.
Ein Web-Scraper kann diese schwierigen Aufgaben für Sie erledigen. Mit der Scrapestack-API können Websites einfach nach Daten durchsucht werden. Mit der Scrapestack-API können Websites einfach nach Daten durchsucht werden. Sie suchen einen leistungsstarken und erschwinglichen Web-Scraper? Die Scrapestack-API kann kostenlos gestartet werden und bietet viele nützliche Tools. Weiterlesen . Scraping-Frameworks sind in Python, JavaScript, Node und anderen Sprachen verfügbar. Eine der einfachsten Möglichkeiten, mit dem Schaben zu beginnen, ist die Verwendung von Python und Beautiful Soup.
Schaben einer Website mit Python
Für den Einstieg sind nur wenige Codezeilen erforderlich, sofern Sie Python und BeautifulSoup installiert haben. Hier ist ein kleines Skript, mit dem Sie den Quellcode einer Website abrufen und von BeautifulSoup auswerten lassen können.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Ganz einfach, wir senden eine GET-Anfrage an eine URL und fügen die Antwort dann in ein Objekt ein. Beim Drucken des Objekts wird der HTML-Quellcode der URL angezeigt. Der Vorgang ist so, als ob wir manuell auf die Website gegangen wären und auf Quelltext anzeigen geklickt hätten.
Dies ist eine Website, auf der jeden Tag CrossFit-Workouts veröffentlicht werden, jedoch nur eines pro Tag. Wir können unseren Scraper so bauen, dass er jeden Tag das Training erhält, und es dann zu einer aggregierten Liste von Workouts hinzufügen. Im Wesentlichen können wir eine textbasierte historische Datenbank mit Workouts erstellen, die wir leicht durchsuchen können.
Die Magie von BeaufiulSoup ist die Fähigkeit, den gesamten HTML-Code mit der integrierten Funktion findAll () zu durchsuchen. In diesem speziellen Fall verwendet die Website mehrere "sqs-block-content" -Tags. Daher muss das Skript alle diese Tags durchlaufen und das für uns interessante finden.
Darüber hinaus gibt es eine Reihe von
Tags im Abschnitt. Das Skript kann den gesamten Text aus jedem dieser Tags einer lokalen Variablen hinzufügen. Fügen Sie dazu dem Skript eine einfache Schleife hinzu:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Voilà! Ein Web Scraper wird geboren.
Scaling Up Scraping
Es gibt zwei Wege, um vorwärts zu kommen.
Eine Möglichkeit, Web Scraping zu erkunden, besteht darin, bereits erstellte Tools zu verwenden. Web Scraper (großer Name!) Hat 200.000 Benutzer und ist einfach zu bedienen. Außerdem können Benutzer mit Parse Hub verschrottete Daten in Excel und Google Sheets exportieren.
Darüber hinaus bietet Web Scraper ein Chrome-Plug-In, mit dem Sie die Erstellung einer Website visualisieren können. Das Beste ist, dem Namen nach zu urteilen, OctoParse, ein leistungsstarker Schaber mit einer intuitiven Benutzeroberfläche.
Nun, da Sie den Hintergrund des Web Scraping kennen und Ihren eigenen kleinen Web Scraper anheben, um in der Lage zu sein zu crawlen und auszuführen. Erstellen eines einfachen Web Crawlers zum Abrufen von Informationen von einer Website Erstellen eines einfachen Web Crawlers zum Abrufen von Informationen von Website Wollten Sie schon immer Informationen von einer Website erfassen? Sie können einen Crawler schreiben, um auf der Website zu navigieren und genau das zu extrahieren, was Sie benötigen. Alleine mehr zu lesen ist ein lustiges Unterfangen.
Weitere Informationen zu: Python, Web Scraping.

